WhatsApp is a closed silo — you can do with it only what the company chooses to let you do. Like Facebook. They can start placing annoying adverts, restrict what external systems you can integrate with, introduce charges for services that were once free, and change their terms of use in any way they like at any time.
Yes, they provide a useful service, for free. But you get sucked in, then you get locked in.
Matrix is Open (as in freedom, liberty) — you can move to another Matrix service provider and still talk with everyone, no matter which Matrix service provider they signed up with. Your work, university, or friends can host their own Matrix server, control their own data, modify it to talk to other systems, and customize it as they wish.
If you care about freedom of communication, use Matrix!
I received an invitation to click to petition MPs to reject the Brexit deal.
What happens if we try to stop it now? I couldn’t find an answer in the linked material. I was quite persuaded during Any Questions on Saturday by a panelist’s argument that although the whole thing was and is a bad deal, at this point getting it over and done with so we can get on to more important things is better than dragging it out.
In all likelihood, […] a majority of ordinary Britons would vote for Remain if a second referendum were to be held today. So, should there be a second vote, once the terms of the negotiated Brexit are known? Six months ago, I thought a second referendum a good idea. Today I don’t. There isn’t time, and making that kind of a decision isn’t the public’s job. It never was.
but then he seems to be saying recently that our politicians might choose to “throw the question back to the people” because they themselves aren’t willing to make that decision, and that that might be “very winnable”.
Exactly what kind of relationship we have with the EU isn’t the most important thing. We can work with it one way or another. The more important thing is how all the anger of polarized opinions divides and hurts people and diverts us from more positive and urgent pursuits.
But never try another referendum. Haven’t we learned that lesson the hard way? A crude question divides a nation, driven by emotions not on the ballot paper, paralysing politics for years to come. If your confirmation bias draws your eyes only to stories that tell you the tide is turning, cast your eyes occasionally at how Murdoch, the Mail and the Telegraph still ply their venom. They would still be there, poisoning the air, in a second referendum.
Another comment saying “I can’t believe you haven’t fixed this bug yet!” A recent example in issue SVN-2507 prompted me to write this response to everyone who feels the same.
I understand your frustration. I’d love to fix this bug. I admit it’s our fault this problem exists, and I am embarrassed that we have not fixed it after so many years.
But who are we? Subversion is an open source project, developed by whoever wants or needs to develop it. “We” are myself, a part-time developer with my own priorities, and a small handful of other developers who contribute to Subversion development a few hours a week at most, with their own priorities. And … You.
How much do you and your company value a fix for this problem?
Can you allocate somebody to work on it for a few hours a week? The current developers, including myself, would be glad to help that person through all the stages.
Can your company offer X pounds or dollars for a freelancer to fix it, on one of those websites? Ask us for help with estimating the cost.
Do you pay for any Subversion services? If so, ask your supplier. If you are a customer of Assembla, for example, then you can raise the priority on my personal priority list.
Can you personally make progress towards a fix? Think through the problem and discuss a proposal? Create some sort of mock-up? Interaction like that often gets other volunteers interested.
As things stand, to my regret, “we” still can’t fix this bug…
Until “we” includes “you”.
Thank you for using and supporting open source software. (I understand you personally may not be able to do any of these things. That’s alright. Even then, you are still supporting Subversion in other ways.)
While the WC also supports merge conflict resolution, a mixed-revision base state, commit of selected parts, and many other additional features, the fundamental purpose of the WC is to help the user prepare, review and commit a set of changes which will create a new revision in the repository.
On the repository side is a similar but simpler mechanism. The FS “transaction” API, designed for programmatic rather than human users, allows the system to prepare and commit a set of changes built upon an existing revision, and commit the result as a new revision.
It is really quite important that WC modifications and FS transactions have exactly compatible semantics for the changes that they represent.
It is really quite important for the feasibility of writing higher level code such as shelving, that WC modifications can be read and written by a common, abstract, interface. That is, an interface definition which enables a ‘copy’ function to plug an input interface to an output interface and push all the changes through the pipe.
To better support these needs, changes in the WC should share an API with changes in the repository.
WC mods API := (basic changes API) + (lots of WC-specific API)
There are two levels at which we can perform this API refactoring. First, streamy changes via the delta editor API. The repository side already has a commit editor for input and a ‘replay’ edit-driver for output of the changes in one revision. The WC already has a commit edit-driver for output, but no editor for receiving modifications. It needs one.
Second, underneath the delta editor APIs on the FS side is a random-access API for reading and writing the modifications in a transaction: ‘txn_vtable_t’. On the WC side we should be able to use the same API as a base, minus the few FS-specific bits, and extended with lots of WC-specific features.
The common APIs for basic changes could be:
basic changes API (streamy): delta-editor.
basic changes API (random-access): most of root_vtable_t.
Also the WC base layer corresponds to the base revision of a FS transaction, again with a lot of WC-specific extensions. Again, common APIs should be used as the base API for reading and writing that base, extended by a WC-specific companion API. In the FS API, the same vtable is used for a rev-root as for a txn-root; each method that does not make sense on a revision returns an error at run-time. In the WC, the base layer is modifiable, albeit with its own semantics.
The common APIs for the WC base layer and the FS txn base revision could be:
basic base-layer API (random-access): most of root_vtable_t.
There are more parts to talk about: streamy base-layer creation (‘checkout’), WC-shape/layout/viewspec API, and so on, but let’s start here.
WC streamy input/output editor APIs
WC replay delta
drives a delta-editor, like ‘commit’ does
thin wrapper around ‘harvest_committables’ and ‘svn_client__do_commit’
will be used for ‘shelve’
WC replay wc metadata
transmits WC-specific local-mods metadata
a streamy companion to wc-replay-delta
WC delta editor
receives and applies modifications into the WC local-mods
expects unmodified WC states: no merging except trivial A-or-B merges
write from scratch
will be used for ‘unshelve’
use it for all existing WC modification ops (‘svn add’, ‘svn propset’, etc.)
what special features does it need, that existing ops expect?
…
add those features in wrappers where possible, else internally
WC-specific metadata editor
applies WC-specific local-mods metadata
a streamy companion to WC delta editor
Definition of WC-specific local-mods metadata API:
includes: conflicts, missing/obstructed, …
I am starting with this streamy I/O layer because I can use it to improve shelving.
The “WC replay delta” is simple and about ready to commit. Implementation of the “WC delta editor” is in progress. I will now look into designing the streamy WC metadata APIs.
Tried on-line supermarket shopping? It often takes me longer than real-life shopping, in terms of finding things. It’s great to be able to do it at all, but the product search interface is terrible. Imagine how much better it could be.
Let’s remind ourselves what it’s like walking into a current on-line supermarket to buy some sugar.
Dear shop assistant, I want to buy some sugar. You are holding up in front of me a long list of little boxes, each containing one bag of sugar, in an order that looks to me more or less random but you claim is “relevance”. Relevant to whom?, I wonder, beginning to feel you don’t understand me. Ah, there near the top is the own-brand white granulated sugar. That’s quite likely what I’ll choose. But no, that’s such a small pack. Do you have a bigger one? I beg your pardon, did you say I have to keep scrolling through the whole list and searching with my eyes to see if I can spot any other sizes that match the same description? Oh, please, won’t you just tell me?
If I were in the real shop, looking at the shelves, I would find the same products laid out sensibly: major groups from left to right, the basic cheap varieties towards the bottom, the expensive and wacky varieties at the top, and for each product type and brand the different pack sizes are next to each other.
How about showing me a photo of the real shop? I could point to what I want more quickly than searching through your list of little boxes.
Let’s try virtually walking in to the (fictional) Dyson-Apple-Google On-Line Grocery Shop.
Dear shop assistant, I want to buy some sugar. You are holding up in front of me a huge picture that looks rather like the shelves in your real shop. On the left I see the white sugars, then a column of brown sugars, then of alternative sweeteners. Towards the bottom are basic cheap varieties, and higher up I can see some wacky and expensive ones, and it looks like I would see more of those if I were to pull the picture further down. Niche products like those are in little boxes, but today I want ordinary sugar so my eyes focus on the products that occupy a larger shelf space. There! A huge bag of the own-brand white granulated sugar standing at the back of the shelf, with one of each of the smaller sizes standing in front of it. The label tells me the price per bag and per kilogram for a typical 1.5-kg bag as well as for the biggest and smallest sizes.
Today I want to order a big bag, as I won’t have to carry it home myself, so I click on the back of the shelf. The whole display changes, subtly but surely, to highlight which other brands and product lines also offer a pack size somewhere in the region of the one I selected. Maybe there is a less popular variety that I’d be interested in choosing instead. With a quick glance, I can see two alternatives. One is emphasizing it’s Fairtrade, in contrast to the product I have selected, and the other emphasizes that it’s British, both characteristics that I support in my buying choices; maybe the system has noticed that. The colour-banded price-per-kg indicators are showing me that one is considerably dearer than the own-brand while the other is only a little more.
Sold. Easy decision.
I know that developing that kind of shopping software is a lot of work. You can’t just tweak the existing little-boxes software. But, dear on-line shop assistant, that’s the kind of shop I would like to shop at.
Subversion 1.11 is the first of the new 6-month regular releases with an emphasis on introducing new features more quickly and a shorter support period. For those requiring stability we have Long-Term Support releases; this is not one of those. For details see How We Plan Releases.
Additions to svn info –show-item (‘schedule’ and ‘depth’)
Most interesting from my point of view is the already considerable enhancement of shelving compared with 1.10. No longer do we store the shelf as a patch file, but as complete before-and-after content, and we apply it in the same way ‘svn update’ or ‘svn merge’ would, except without (yet) any conflict handling.
The 1.11 version of shelving also adds a limited form of checkpointing, in the form of multiple versions of a shelf. It is analogous to how we might manually save “my-change-1.patch” and then a later version as “my-change-2.patch”. Shelving in Svn-1.11 summarizes the changes and gives an overview.
I should point out that while shelving is enhanced, it still has a substantial gap: it lacks support for copies and moves, and mkdir and rmdir. To fill this gap I am working now to put in place consistent internal APIs through which to push and pull changes into and out of the working copy storage layer. With those in place, an implementation of shelving that supports the full range of WC operations should be as simple as a glue layer that plugs a “pull from WC” API into a “push to shelf” API, and vice-versa.
The other notable improvement listed in the 1.11 release notes is one that Stefan Sperling has been devoting a lot of effort to:
This week the Matrix core team launched hosted Matrix servers at Modular.im.
This is excellent news as I expect it will boost the take-up of Matrix. I would like to see organizations using Matrix in place of IRC, Slack, etc. The early adopters are likely to be those into open source such as (I hope) the Apache Software Foundation, although perhaps commercial organizations are more likely to pay somebody else to run a hosted service.
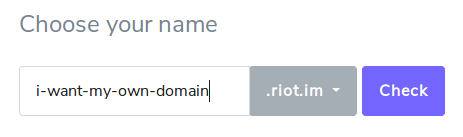
But there is a catch, at present. Using your own domain name is only offered on Modular’s large plans. I think this is a mistaken policy.
My reasons for embracing Matrix can be summarized as “Own Your Own Identity and Data“. It is essential to identify myself using my own domain name — @julian:foad.me.uk — and not by choosing a username or subdomain in a domain controlled by the provider company.
I believe it is essential for the future health of Matrix that we encourage users to bring their own domain name. That will teach users about decentralization, empower them to change their hosting provider, and encourage developers of other software in the ecosystem to embrace decentralized design. If we expect users to default to registering on a large central server, then the system is in danger of degenerating into an almost centralized future where many bridges, integrations, and other ecosystem components would only support the the large central servers, and most users would feel like it was just another silo. That would be a failure.
If you register your interest in Modular’s future smaller plans, you may receive a survey invitation, as I just did. I took the opportunity to let them know my thoughts. If you care about this sort of thing, perhaps you could do so too.
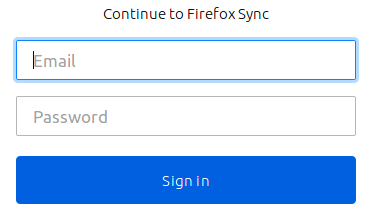
If there’s one thing that reinforces the expectation that BigCorp controls my data, it’s a login like this:
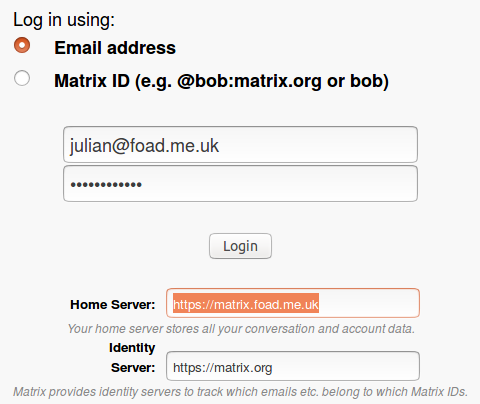
You can use your own sync server if you are prepared to configure the sign-in procedure like this:
To configure desktop Firefox to talk to your new Sync server, go to “about:config”, search for “identity.sync.tokenserver.uri” and change its value to the URL of your server with a path of “token/1.0/sync/1.5”:
That’s if you ever guessed it was possible and went looking.
I would love to see Firefox promote owning one’s own identity and data, by prominently displaying the option to use one’s own server. An example from Matrix:
I was mentioning my Matrix user id in my last blog post, and I wanted to mark it up as a hyperlink so that readers could click on it to contact me through Matrix. Or rather I want that to be possible in general.
Perhaps a URL scheme is a good place to start. How will software know to act on it? Before it’s universally implemented, we might expect to install a browser plug-in to act on it. What should it do? Bring up the user’s preferred Matrix message composer, if and when such a thing is configured in the user’s operating system (as is nowadays common for email links and some other kinds of links). Alternatively, bring up a “compose” action in some web UI that the plug-in knows about, such as https://riot.im/app/ .
Has anything like this been declared or implemented yet?
and the page has a link to issue #455 tracking this problem.
Close
No ad-blocker?
Dear visitor, this is from me, Julian, not a commercial/legal pop-up. More...
I'm a quiet person, enjoying a quiet and safe online experience. If you'd like that too, consider installing a browser extension, an ad blocker. We all should. It hides the insidious ads. It also blocks malicious surveillance and tracking scripts, protecting our privacy and security. Learn how and why: shouldiblockads or Stefan Bohacek.
You may close this message. Unless you clear cookies I won't bring it up again. And sorry if this detector erred. --Julian