This is important. Watch Jasper Nuyens’ FOSDEM talk about Tesla hacking and the FreedomEV project:
https://archive.fosdem.org/2019/schedule/event/tesla_hacking/
This is important. Watch Jasper Nuyens’ FOSDEM talk about Tesla hacking and the FreedomEV project:
https://archive.fosdem.org/2019/schedule/event/tesla_hacking/
For individuals, Matrix's identity scheme creates lock-in.
How to fix?
I love Matrix. I think it’s the way forward for libre/open (as in freedom) personal communications, with a real chance to free users from the lock-in of popular silo messaging systems like Whatsit, Facepalm and Twiddle. I run all my own messaging (except email) through Matrix, with bridges to the silos that my friends still use as well as SMS and IRC.
At present, unfortunately, there is a big obstacle to me recommending any friend or family member to sign up to Matrix: identity and server lock-in.
An Open system with lock-in? Ugh. What went wrong?
To use a silo, you register an account and either you are identified by your telephone number or you choose a username. (You can then set some account options, usually including a “display name” which you can change from time to time.) Now, what if at some point you dislike that silo’s rules or advertising or charging? You’re stuck. They deliberately designed the system so that nobody has any options other than continue or quit.
To use Matrix, you register an account on a server. You first need to choose a server, which is identified by its Internet domain name such as matrix.org, or mozilla.org, or my-own-server.my-name.me if you run your own server. You can find out which servers are available for public use. Some are free of charge and others require payment, similar to email services. Having chosen a server, you pick a username and are then identified globally as @username:servername . (You can also choose a display name.)
Matrix right now is great for an organization: running their own server on their own domain, they control their own rules and namespace for users, rooms and groups.
If you are a normal person, your default option is to register a username on ‘matrix.org‘. (In principle there will be other public servers but there are hardly any so far.) Then, that username is tied to that server forever, or at least until Matrix developers invent a way out.
This lock-in is different from a silo. At least with Matrix you can create a new account on another server, to get away if you don’t like the old one. What you can’t do (yet) is migrate your old account to the new one. Not in any way. See “Account Migration” below.
One way to mitigate the account migration problem is to register an account under a server domain name that you control.
The point is, then, the user controls their own domain name registration, which is directly registered with a domain registrar, outside the control of and Matrix or other service provider. The user can keep their own domain and have it served by a new server in the future if the current server becomes unsuitable or unavailable.
How feasible is this, today?
Hosted servers come with significant limitations on customizing your server. For example, on modular.im (currently the main hosting option), AFAIK you cannot run the Whatsit bridge.
What can we do to improve things for the normal user?
Who should be doing this? Not necessarily the Matrix Foundation or New Vector (who make Riot and Modular.im among other Matrix things). They have limited resources and their own priorities. It’s an open-source system so anyone wanting these things should get involved and start making them.
Good places to discuss and get involved in the self-hosting side include #matrix-docker-ansible-deploy:devture.com and #matrix-self-host-onboarding:chat.weho.st .
It would be useful to be able to migrate an old account to a new one in ways like:
I was thinking about what is possible in email, and what regrettably isn’t available. Migrating an email account is not at all simple, but most of the mini-features above are possible to some extent. One thing regrettably missing in the email system is a way to automatically inform senders to an old account that they should update your address and re-send to a new account. (Like an HTTP “redirect”.)
It would be useful to develop those kinds of mini-features for making the transition to a new matrix account smoother. That might be a feasible short-term mitigation.
However, there is a better long term solution: decoupling accounts from identity.
[TODO: Write about decoupling identity.]
I fired up https://meet.jit.si/ just to explore how it works. Following the hint, I chose a simple phrase for the meeting name, something like “MyFamily”, and hit “Go”.
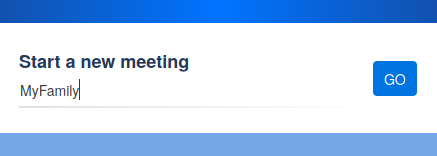
A blank meeting screen.
Six elderly people whom I don’t know, talking to each other, looking surprised to see me and saying “Oh, who is that?!”
I left the meeting after a few seconds. Perhaps they worked out what happened and how they could change their settings to stop strangers intruding. Perhaps they were worried. Perhaps I could have gone back in and explained that I walked in on them unintentionally and meant no harm. Perhaps.

There is a UI/UX problem here. Jitsi-Meet is insecure by default. Certainly it’s possible to use it in a more secure way, but that is not good enough.
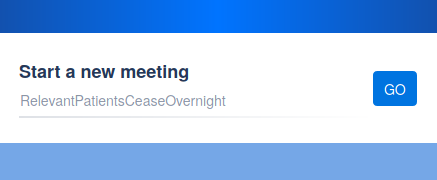
The UI here is supposed to suggest that I can use a randomly generated phrase as a meeting name. The designers clearly intended that as a security measure: a sufficiently unguessable name is secure against accidental visits, and forms a part of the security measures against intentional attacks. I know that from my background knowledge of security practices and software design. From further background knowledge and exploration, I also know that I can press “GO” to accept the suggestion. But still I fell into this trap.
As a new user, it looks like I need to enter something, and I would expect to enter a simple and meaningful name, and would absolutely not expect that doing so would immediately remove the expected privacy.
Filed as a bug: https://github.com/jitsi/jitsi-meet/issues/5407 “Choosing a meeting name is insecure by default”
## Description
In real life just now, I chose a simple meeting name, something like "MyFamily" (but not that) and hit "Go". I saw and heard six elderly people whom I don’t know, talking to each other, looking surprised to see me and saying “Oh, who is that?!”
Their privacy was violated to me, and mine to them.
This is insecure by default, and inconsistent with claiming "security".
Reported here: https://blog.foad.me.uk/2020/03/26/jitsi-meet-excuse-me-who-are-you/
---
## Current behavior
On entering a simple meeting name there is a real chance of walking in on someone else's meeting, uninvited.
---
## Expected Behavior
On entering a simple meeting name, there should be some protections in place to prevent walking in on someone else's meeting, uninvited.
---
## Possible Solutions
There are several possible solutions and measures, including...
* explain about the random phrase and its security implications and make accepting the suggested phrase a more discoverable option;
* have the "create meeting" UI user choose whether they want a public/open meeting or a private/closed meeting;
* if a user-specified meeting name is chosen for a new meeting, then very strongly encourage setting a password (unless explicitly chose to start a public meeting);
* when "start a new meeting" UI leads to joining an existing meeting, that is a violation of expectation, so interpose a second step, e.g. "this already exists; try to join it or choose another name?"
* interpose a "new user is knocking on your door" step whereby existing participants have to explicitly accept the new user;
etc.
---
## Steps to reproduce
* one user uses the "Start a new meeting" UI using a common phrase like "MyFamily" as the name;
* another, supposedly unrelated user uses the "Start a new meeting" using the same common phrase like "MyFamily" as the name;
* see that they join, without protection;
---
# Environment details
Using https://meet.jit.si/ on 2020-03-26.
Sharing links to Matrix users or rooms or messages is broken. The “matrix.to” service currently does not “cut it” for federated use.
A standard matrix: URI scheme is proposed as a superior solution, but that is far from ready and we need a usable interim solution.
Where are we with having links like https://matrix.to/#/@nukeador:mozilla.org to suggest chat.mozilla.org? …
Rubén Martín (nukeador)
To make this interim matrix.to service work satisfactorily with a federated matrix network, while it lives at a centralized URL, we need to make it support decentralized use cases as far as possible.
Problems, in terms of design issues:
http://t.me/<channel> for examplematrix: scheme links, initially as an advanced option, for those who are starting to test or use themMany of these issues can be improved by changes to the central “matrix.to” web site.
I propose the following changes to the matrix.to service:
Together, these might address the most pressing of the usability issues.
(The last item, adding “matrix:” URIs, is important in a different way. Rather than solving an immediate user need, it promotes development of the matrix ecosystem towards replacing this interim system with a better one.)
One issue remains. The fact that federated server admins can’t customize the experience is hard to avoid. Some options are:
I am trying out these ideas. I will make source code and a demo available when I get around to it. I will update this post below, as and when I do so. I will listen to your feedback (in the Matrix room #matrix.to:matrix.org please, rather than blog comments) and incorporate your suggestions where they make sense to me.
Some early draft mock-ups:
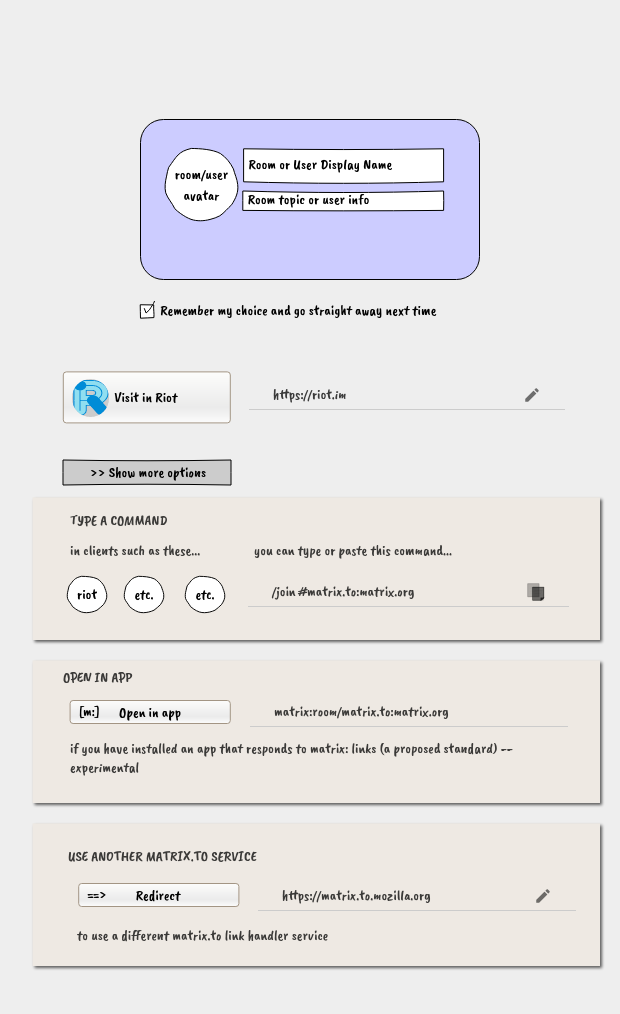
Please join myself and others discussing this in the Matrix room #matrix.to:matrix.org .
This is a review of the development of experimental support for shelving in Subversion. Shelving v1 was released in Subversion 1.10, shelving v2 in Subversion 1.11, and shelving v3 in Subversion 1.12. These versions are not a linear sequence of improvements but rather three different designs, each developing a different aspect, with different pros and cons.
Shelving has been on the Subversion developers’ wish list for a long time. This item was initially picked by my employer to be a bite-sized task to show off creating a new feature. The idea was that we could quickly make a wrapper around “svn diff” and “svn patch” that would save the user’s changes into a file, revert those changes from the working copy, and later apply the changes back to the working copy. A built-in light-weight patch management feature.
Other popular version control systems have their own kinds of shelving. For example, git has a simple and powerful “git stash”, and perforce neatly treats “shelved” as one possible storage state of a changeset, like a variant of “committed”.
I started by reviewing the kinds of shelving that have been proposed for Subversion in the past, and the facilities offered by other version control systems, and sketching some ideas of what a shelving design for Subversion could look like, ranging from light-weight management of patch files through to DVCS-like local branching. One notable idea, yet to be developed, was that we should integrate the existing “changelist” feature into shelving: “shelve” would mean moving a changelist from the WC to a shelf, and “unshelve” applying a changelist from a shelf to the WC, all the while keeping track of it by its name. But first we would need something as simple as possible, a place to store shelved changes, and mechanisms to shelve and unshelve changes.
In the wish list along with shelving was also the idea of checkpointing one’s work in the working copy. The idea was along the lines of taking a snapshot of the working copy before making changes, so that we could roll back to an earlier state if the changes didn’t work out, particularly if the changes were something like an “update” that changes the WC base state, or a merge that might result in conflicts.
I had been involved in previous discussions around this idea, when the focus was on how we could implement snapshots within the WC DB. My own view of the WC DB is that its design and implementation is far too hairy and fragile to attempt something like this at the low level. I could imagine a design at a higher level where snapshots are saved more or less like commits in a repository. The architecture of Subversion’s client side and working copy is too far removed from the repository architecture to make that a feasible integration in the current code base. I did explore embedding an actual Subversion repository, or some layers of a repository, to use as a shelf storage unit. There are some possibilities there but not in a short term development.
Instead I re-imagined checkpointing as referring to taking snapshots of work in progress in the form of a series of numbered patches, capturing only the committable changes but not the WC base state. This would not provide the ability to roll back after a bad update, which is a pity. However, it would be useful. The evidence of this is that developers including myself already tend to save a series of numbered patch files to capture iterations of our work in progress, in certain cases where we feel committing is not appropriate or not convenient.
Therefore I ended up lumping the terms “shelving” and “checkpointing” together, “shelf” referring to a series of snapshots sharing a common name, description, and WC base; and “checkpoint” referring to one numbered snapshot within a series. Thus these would become light-weight UI mechanisms on top of the same underlying implementation which I refer to generically as shelving.
We recognized from the outset that “svn diff” and “svn patch” do not support the full range of changes that Subversion can represent in a commit. They have no way to represent “binary” file content, nor copies and moves, nor creation and deletion of a directory. Defining representations for all types of change has been on the wish list for ever, and was something I thought we could come back to later, after implementing shelving of the currently supported change types. It is almost an orthogonal issue, with little bearing on the patch management layer other than defining a suitable failure mode when unsupported change types are present.
Shelving v1 therefore is basically a user interface for writing the output of “svn diff” into a named and numbered patch file, optionally running “svn revert” on the affected files, and later replaying a selected patch file into “svn patch”. Minor additions include saving a descriptive message, like a commit log message, for the user’s reference.
Handling of unsupported change types is rudimentary. A shelving attempt fails if unsupported changes are present in the requested scope. An unshelving attempt fails if any local modifications are present in the working copy among the paths to be unshelved. At least that is what the command-line interface implements. It was necessary to provide some checking or “dry run” APIs so that the client code could fail gracefully and let the user know that unsupported changes were going to prevent shelving or unshelving. Especially the latter, as we do not want the client to start applying changes to the WC and then hit a failure part way through, as the WC interface provides no roll-back mechanism to recover cleanly in such a case.
A more sophisticated client might want to offer the option of skipping unsupported changes instead of completely refusing to shelve anything. However, skipping some changes can lead to further difficulties. For example, if we skip shelving a “rename directory”, that makes it awkward to shelve and unshelve any changes that occurred inside that directory. Therefore keeping the options simple and crude was the most expedient decision to get something useful working.
This implementation was released as an experimental feature in Subversion 1.10.
Patch files are all very well for text changes, but a large class of customers who pay for Subversion hosting are games developers who use Subversion because of its support for large binary files such as images and videos. What can we do to enable shelving those?
We could upgrade the patch file format to include binary data, perhaps encoded into some text-compatible form.
Or we could store file blobs as separate files.
There are trade-offs. Speed is a concern, as “binary” files tend to be large. Using whole files brings the possibility of moving files on the filesystem when the user does not need to keep a copy, and perhaps using linking or copy-on-write semantics when they do. Using a patch, we would be encoding and decoding the binary blobs into a patch stream, which means linear processing on every use. The patch format is not natively indexed for quick seeking, so that limits all accesses to the patch, even accesses to small files, unless we invent and add an index.
A second concern was patch application versus 3-way merging. A patch is a context diff. It stores the before and after version of each changed hunk, and a little context around each hunk, but not the whole original file. Applying a patch works reliably when the file we’re applying it to is the same original file as when the change was shelved. If not, perhaps because we updated and fetched changes that somebody else committed in the mean time, then applying a patch works only so far. It works when the changes being unshelved neither overlap nor functionally interact with changes that were brought in by the update. There is no way to convert the patch application to a 3-way merge and review the two sets of changes independently, unless we were to read the original version numbers from the patch file and fetch those versions from the repository.
A better position to be in, when resolving conflicts, is to have immediate access to all the versions we need for a three-way merge. The original base version of the change, and the whole changed file (which we can either store explicitly, or reconstruct from base + patch), and the new base version onto which we want to apply the patch.
The three-way merge enables (1) more robust merging of text changes, because the whole context is available to inspect, not just bits of context; and (2) the possibility of merging non-text files such as images, or arbitrary document file types, by using an external three-way merge tool that understands those file types.
We changed the shelf storage implementation to store the ‘before’ and ‘after’ version of each changed file, for all files. (Also for property changes.) No more patch file.
To apply changes, it uses a 3-way merge per file. It does not yet use a 3-way merge for tree changes. It is not yet integrated with the merge conflict handling mechanism that ‘update’ and ‘merge’ commands use.
This version was released in Subversion 1.11.
For the next version of shelving I determined to address the architectural problem. What problem? The storage for a shelf needs the same core semantics as the WC: a base layer plus some committable modifications. The WC had no generic API for “read the committable changes”, nor for “write these changes to the WC”. The core operations of shelving should be as simple as two pipes:
The core of “shelve”:
The core of “unshelve”:
What was it like before?
Shelving v2 walked the tree of WC paths “manually”, calling separate API functions to read and write each little bit of user data (file text, properties, directories). The API for the shelf storage was completely different from the WC API. For one conceptually simple job, copying changes this way or that way, there were two large chunks of manually written code, with no re-use and lots of room for bugs.
Shelving v1 used the API of “svn diff” and of “svn patch”:
That had the desired properties of re-using generic APIs and using a single API entry point to process the whole tree, but it did not have the right semantics for the stored changes. As a context diff, it lacked the base version, and the patch format lacked support for binary data, mkdir/rmdir, copies and moves.
Shelving v3 adds APIs to libsvn_wc that are analogous to “diff” and “patch” but instead of streaming the changes to or from patch file format they connect to the existing “delta editor” API which is what Subversion uses to transfer changes to and from the repository, in commit and update operations. The delta editor API is the “pipe” in the core operations of shelve and unshelve:
Providing the new wc.read_changes() involved a relatively simple extraction of part of the existing WC “commit” logic, removing all the repository-specific details to leave just the core function of sending changes to a delta editor. (This new API is actually named “svn_client__wc_replay”.)
The new wc.write_changes() API was written from scratch. (This new API is actually named “svn_client__wc_editor”.) Ideally this might have been extracted from some existing code such as “merge”, “patch”, or “update”; but “merge” and “patch” both work with context diffs rather than the delta editor interface, and the implementation within “update” was not readily re-usable. One place was found where this new API could be re-used as a drop-in replacement: in the implementation of repository-to-WC copy, which previously incorporated a dedicated delta editor that only knew how to apply “add” operations.
Next we needed to re-implement shelf storage in such a way that we could store the base of the changed files/paths, and write and read changes on top of that base via a delta editor API.
The quickest ways to create a WC base layer are the same ways we currently get a WC: either “checkout”, or copy an existing WC and revert the local modifications. Neither is ideal, but both work.
Ideally, what we want for the shelf base storage is some sort of skeleton tree that includes only the paths that have shelved changes, and storing for each such path just a reference to the existing WC base storage. This would take very little space and time. The APIs to accomplish this have not yet been developed. (They are needed not only for shelving but also for “view specs”, a requested feature for saving and restoring the WC base shape.)
In order to prove the concept of using the delta editor API for shelving, “checkout” is initially used to create a WC base for each shelf. The down-sides to this are of course that unless there is a very fast connection to the server this can take a long time, and it is heavy on disk space because it is not constrained to just the shelved paths.
Currently Subversion the project has insufficient developer resources to continue these developments. If and when a volunteer or paid developer wants to take up the development, here are some suggestions.
Making a copy of the WC base state more efficiently is the first priority. The WC design does not seem amenable to cleanly creating a WC whose base layer is a reference to the base layer in another WC, nor to cleanly creating a “shelf” working layer inside the main WC that refers to the existing base layer. A quick-and-dirty approach could be to copy the whole WC and revert all the changes. To do the same but copying only the metadata “.svn” directory without copying the working files, might require modifying the revert code to make it work in fully “metadata-only” mode, which would be a useful upgrade anyway.
Shelving v3 currently fails some of its tests. Some are related to “mkdir”, which may require a relatively minor fix. Some are related to merging when applying changes into a WC that no longer matches the original base state. This is because the “apply” code does not attempt merging. Somehow the “apply” code needs to be hooked up to a merge. Subversion’s main merge code is unfortunately not in a good state to be re-used like this. It may be desirable to implement a “merge” alternative to the simple “apply” API (svn_wc__editor).
[UPDATED 2020-03-24] Subversion 1.14 LTS is due to be released soon. Subversion 1.14 looks set to include shelving v2 and v3, disabled by default and opt-in by setting an environment variable. The reason for making them disabled by default is that 1.14 is intended to be a long-term support release focusing on stability rather than experimental features.
Also published at: https://cwiki.apache.org/confluence/x/MxbcC
I am testing SmsMatrix, an SMS-to-Matrix bridge on Android. It is one of many Matrix bridges. But this post is not mainly about SmsMatrix, it is mainly the start of a train of thought about how we can manage communications with one person bridged over different channels.
This is a write-up of thoughts I first posted to the SmsMatrix discussion room, which would be better continued on #bridges:matrix.org.
Let’s say my friend has telephone number 123456 and is in my phone’s address book as “Ray”.
When my phone receives an SMS from Ray, SMSMatrix sees that message arrive in the Android SMS subsystem, and (if it hasn’t previously done so) it creates a new Matrix direct-chat room which it will associate with the SMS sender’s phone number, and invites me to join the room.
The other participant in this room is the bridge bot. Its username is @sms-bot:my_hs, and it sets its own display name to “Ray”. I assume that is a per-room display name, so it will show as a different name in each SMS conversation. The bot does not set a room name, and so Riot displays it as “Ray” (the other participant’s display name), and the bot sets the room “topic” field to “123456”, which Riot displays next to the room name. The idea is that in the user interface it looks like I am having a chat with “Ray” and it works like I am having a chat with Ray.
In Riot-web’s message view, the sender of this first SMS message shows as (precisely) “sms-bot”. The display name of @sms-bot does seem to be correctly set to “Ray” — I can see that in the “users” panel. Perhaps that’s a Riot bug that it doesn’t always display the user’s display name.
This bot works without admin privileges. It can do so because it doesn’t try to create and control a new Matrix user for each SMS sender, nor does it try to find and puppet an existing “real” matrix user account corresponding to the sender.
I wonder if it would be nice to upgrade it to a puppeting bridge if I one day have enough time to devote to it. I’m wondering exactly what we could achieve if we did so.
I also have some other bridges, and let’s say Ray also has her own Matrix account on her own homeserver, where she calls herself by her full name “Radiator”. Now I have Ray’s messages coming in to me in these Matrix rooms/users:
@sms-bot:my_hs “Ray”
@whatsapp_123456:my_hs “Ray (WA)”
@telegram_123456:my_hs “Ray (TG)”
@ray:rays_hs “Radiator”, Ray’s real Matrix user account
The mautrix-telegram and mautrix-whatsapp bridges each create a new user id for Ray in their own namespace of matrix user-ids, which is different from the SMS bridge.
I am interested in researching how we could improve this situation. Would we want to make all bridges to the same person somehow bridge to the same Matrix user?
@pwr22 asked, “How would the bridge know which method to use when sending a message?” That’s a good UX question. The first thought coming to my mind is that’s easy if we dedicate a separate room for each bridge for that user. (Ray’s SMS chat room, Ray’s Telegram chat room, …).
“In that case what do we gain from having one puppet user instead of separate ones per service?” We gain things like,
I expect users would want to choose, by their own preferences and perhaps per contact, whether a contact’s messages are all grouped in the same room or a separate room per bridge.
If I want to group all Ray’s messages into one room, then the sending UX issue must be solved a different way. Perhaps the client would allow me to set a preference. (That could be stored as client-managed metadata, like how Riot stores some settings in “account data” under “im.vector.riot.xxx” keys.) And/or there could be bot commands so I can tell a bridge "!sms-bot: enable [or disable] sending outgoing messages in this room through SMS".
In response to my thought about making all bridges bridge to the same Matrix user, @swedneck replied, “i’m not sure that’d make sense. i would probably have all those bridges in the same room if possible. you’d probably want his bots to ignore each other though.” So:
@sms-bot:my_hs (“Ray”),@telegram_123456:my_hs (“Ray”),@ray:rays_hs (“Radiator”).I see how that would work well for incoming messages: I would be able to see which bridge each message came through, if I wanted, while keeping all the display names the same if I mostly didn’t care to see the difference.
We would need a way to make the bots know about each other. When Ray sends me a message through one bridge, we (probably) don’t want all the other bridges to send him copies of it. They’re all “my” bots running against my Matrix home server (HS), so I could add something to their configs easily enough. Alternatively, we could define common metadata that they could each set, so they could detect the situation automatically. The latter would be more flexible, in case some of them are not configured directly alongside my HS.
What about when I send messages to Ray? If I just type without a mention, then the same applies as I said before: some way of configuring in advance which bridge(s) is/are to send it.
When I Mention Ray, there are different matrix usernames I might mention, depending how I do it: if I click on one of the received msgs, I might select a bridge username that isn’t the currently configured preferred send method; how should that all work?
Maybe bridged usernames should be specially treated: all treated as something like aliases, and all resolved to the same single “real” matrix username?
Needs more thought.
As part of a solution, we will need a mechanism to allow multiple bridges in a room to communicate with each other. This proposal may achieve it:
A year ago I wrote up some thoughts on Matrix Big Issues. Here is another take on the medium-to-big issues that I think are important and interesting.
As you will see, these are just sketchy notes to record ideas I have been thinking about. I have not had time to research them and write them up further.
(My personal view as someone who runs my own homeserver and is getting involved with Matrix development.)
Matrix needs…
An ordinary user should be able to control their data (message history & media)…
Use cases
And some smaller but still important and interesting issues:
I am leaving my latest job and moving on to my new passion, Matrix.
Recently I have become passionate about the need for modern communications systems that are Open in the sense of freedom to talk to anyone. The currently dominant silos like WhatsApp only let me talk to the friends who are willing and able to subscribe to that company’s terms and restrictions, with no way to get around them when they decide to display advertising to me or stop supporting my mother’s not-terribly-old iPhone. To me, that is like some historical feudal system in which I live as a tenant and I must obtain agreement from the lord of the estate if I want to invite any of my friends to visit me. We need and deserve better than that: an Open way to communicate to our friends and business contacts. Email served that role for the first part of the 21st century, and Matrix now serves that role for the era of instant messaging.
My software development in recent years has been mostly on the open source Subversion version-control system, and I have particularly enjoyed helping to create something so widely used and appreciated. Nowadays its popularity is eclipsed by Git in small to medium sized projects, while Subversion still enjoys a strong following in certain fields such as games development due to its strengths in versioning large data sets and simplicity of usage. Participating in the development of Open Source software has given me the greatest satisfaction in my professional life, and I intend to keep it that way. That is why developing the Matrix communication system is so exciting.
p.s. I am still contracting on Subversion support work, so get in touch if you need any bug fixing or problem diagnosis.
One of my favourite open source institutions is considering replacing their use of an open source tool with a proprietary service “donated” for “free” by its vendor.
It’s time I just said what I think: Encouraging open-source contributors to adopt another proprietary sponsored service is against the principles I want the institution to uphold.
Pootle is an open source tool that assists with human-language translation. Contributors to a project use it to write and contribute translations of open source software into their local language. As with many open source projects, it is under-resourced. Proprietary services look more attractive, if we look as measures such as the immediate user experience and the maintenance burden.
Yet, when we ask contributors to use any “donated” proprietary service, we make those users and the FOSS community bear its cost in the domains of lock-in and advertising. I am disappointed to hear that my favourite institution is seriously considering this. (This is not about translation tools specifically; I feel the same about all the user-facing tools and services we use.)
Don’t get me wrong: I am not suggesting this goes against the institution’s policies, and of course there are hard-to-ignore benefits to choosing a proprietary service. I can’t imagine exactly how much pain it is trying to maintain this Pootle instance. On the other hand I do know first-hand the pain of maintaining a lot of other FOSS that I insist on using myself, and I sometimes wonder if I’d like to switch to a commercial this-or-that. At those times I remember how much I value upholding the open source principles, and I choose to stick with what is sometimes less immediately convenient but ultimately more rewarding.
Time after time I observe the FOSS community suffering from getting sucked in to the traps of commercial interest like this. A FOSS project chooses to use a commercial service for its own convenience, and by doing so it feeds the commercial service, increasing familiarity with it and talk about it (forms of lock-in and advertising), decreasing the development going in to competing FOSS services, making it more likely that others will follow. I observe FOSS people tending to concentrate on the short-term benefit to their own project in isolation, even when they are peripherally aware that their field would benefit in the long run from working together with others on the tools and services that they all need.
What could be the cultural process led the institution to this place?
“Current tools are poor… Let’s try another ‘free’ service to quickly overcome our problem.”
I feel like there’s a cultural step missing there. Where is the step that says,
“We are hundreds of open source developers needing a good translation service. Other open source developers are trying to develop good translation services for people like us. What a great fit! Let’s work together!”?
I would rather join and contribute to a new project group whose purpose is to provide an Open service (in this case for translation) for the institution’s projects to use, doing whatever development, customization, maintenance and IT infra work it needs depending on the state of the available open solutions.
To fill in the missing step, I feel we need to introduce a culture of speaking out at a membership level to say, “Here’s a challenge; who can volunteer to form a group to solve it?” and encouraging members to think of working together on communal service provision projects as a normal part of the institution’s activity.
By working closely with the FOSS people who want to provide a service that we need, our contribution to the upstream software projects would benefit others for the public good, and more generally we would foster mutually beneficial growth and normalization of adoption of FOSS technologies.
I’m not saying it isn’t hard to get the necessary contribution level to make a difference, or that folks haven’t tried before. (Some communal service projects are used in this institution, but they tend to be small scale in-house projects rather than collaborations with other FOSS projects.)
How can we drum up support for doing it the FOSS way?
